クリーンアーキテクチャ(Clean Architecture)はソフトウェアの設計で利用する方針の1つとして有名。
自分もこれまで本を読んだり、Webで検索して知ってはいたものの、その「手法」のみを吸収するという状況でした。
つまり、どういうディレクトリを作るとか、こんな役割を置くとか、「手法」だけ吸収し、その「概念」は置き去りにしたという訳ですね。
しかしそんな中、幸運にも「類いまれなほど優秀な」シリコンバレーのエンジニアたちと話す機会があり、これまでのClean Architectureに関する考えを改めることに。
「類いまれなほど優秀な」というのは、YouTubeやGoogleなどでエンジニアを率いていたり、ベンチャーのCTOをやったりしているシリコンバレーのエンジニアと、ヨーロッパで活躍しているスーパーエンジニア。
この記事は、簡単にClean Architectureの概念について整理し、今回作成したアプリについてまとめたもの。
最後に実際に彼らとの話で得たことについて記してみます。
Clean Architecture
Clean Architecture概要
Clean Architectureとは、Uncle Bob氏により提案されている、言うなればソフトウェアの設計方針。
全てUncle Bob氏が考案した、というわけではなく、いろんな人が提案している手法について考察し、その本質を体系化したと言う方が適切かもしれません。
どんな内容かというと、ソフトウェアの機能を実装するにあたり、クラスやパッケージ、モジュールをどのように分割すれば「いい」のか?、ということに対する1つの回答という感じ。
ここでの「いい」とは、概ね以下のような性質があることを言っています。
- テスト可能であること(ここでユニットテスト、自動テストのこと。)
- 低コストで変更できること(少ない工数で機能追加や変更ができる。)
Clean Architectureでは、これらの性質を獲得するために、関心の分離(separation of concerns)による、依存関係の整理を重視しています。
その際にソフトウェアを複数のレイヤーに分割して設計する方法が提案されています。
では早速、どんなレイヤーに分割しているのか見てみましょう。
Clean Architectureの内容
さて、Uncle Bob氏のブログには、以下のような図があります。
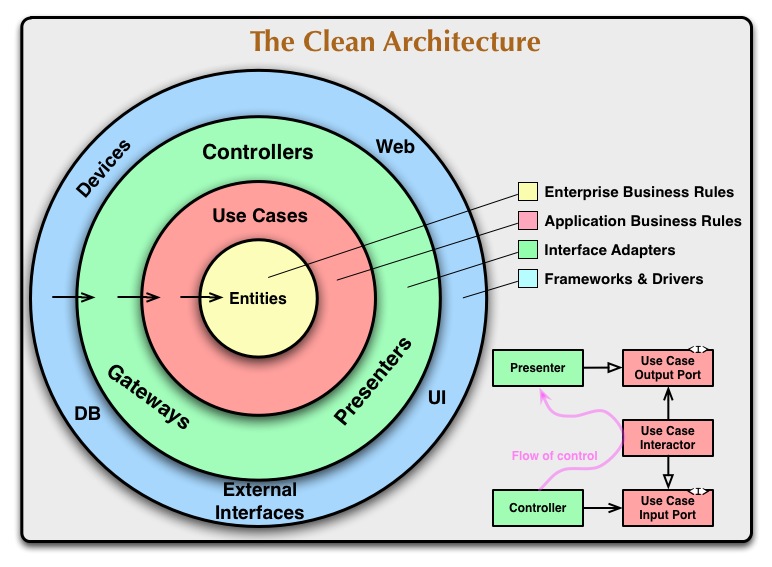
これはしばしば引用されていますね。
なお、この図はあくまで「概要」とのこと。つまり、アプリによってレイヤーを増やすなど調整が必要になるというとですね。
1つ1つ見ていきましょう。
依存性のルール
まずは、この図から依存性のルールを確認します。
冒頭でClean Architectureでは依存関係を整理しているといいました。
それは、このように依存関係が内側に一方向に向くというルールがあるということです。
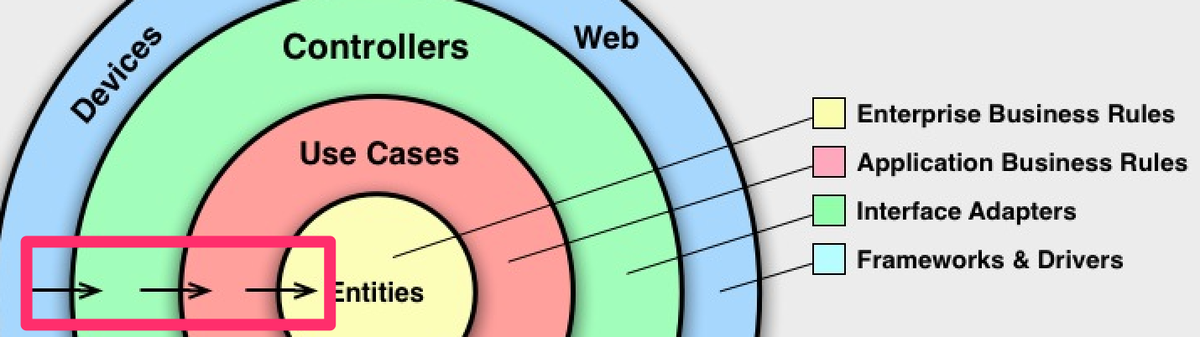
後ほど1つ1つ見ていきますが、この図には4つのレイヤーが定義されています。
各レイヤーには名前がつけられていますが、具体的にどんな要素が該当するかは円の中に書いてあるため、開発経験がある人にはイメージがつきやすいようになっていますね。
- Enterprise Business Rules
- Application Business Rules
- Interface Adapters
- Frameworks & Drivers
そして矢印が外側から内側に向いています。
これは、例えば、「ControllersはUse Casessに依存している(使っている)」と読み解くことができます。
このように、Clean Architectureでは「依存関係が一方向になるよう、整理する」というのがとても重要になります。
4つのレイヤー
さて、この図で上げられている4つのレイヤーを見ていきましょう。
1つ1つどんな役割なのかさらっと確認してみましょう。
※しかし、どんなレイヤーに分割するか、よりも依存関係を整理するという概念の方がより重要です。
詳細はUncle Bob氏のブログを参照してください。
俯瞰すると、
- より内側のレイヤーに行くほど抽象度が高い
- より外側のレイヤーに行くほど、変更頻度が高い
という点もポイントですね。
Enterprise Business Rules
円の一番内側にあります。
ここでは、通常はアプリで利用するデータ用のオブジェクトが入ってきます。
具体的には、User、Account、Productなど、そのアプリで扱う「名詞」を表現します。
それがEntityですね。
なお、このレイヤーは変更する可能性が一番少ないです。
Application Business Rules
Use Casesです。
つまり、そのアプリに特有なビジネスロジックを表現します。
なお、このレイヤーはフレームワークやデータベースなど、外部の要素に依存しないという点に注意します。
つまり、基本的には抽象に依存するということです。
これについては、サンプルのアプリで詳しく見ていきます。
Interface Adapters
このレイヤーでは、外部(データベースやAPI、HTTPリクエストなど)から取得したデータを、次のレイヤーであるUse Casesが使いやすいように整えます。
例えば、データベースから取得したデータをUse Casesが使いやすいようにEntityに変換する、などの役割を担います。
Frameworks & Drivers
フレームワークに関するコードを配置する一番外側のレイヤーです。
このレイヤーでは、内側のレイヤーを利用するためのグルーコード(glue code)以外はなるべく書かないようにします。
UIに関するコードがこのレイヤーに来ると考えるとイメージしやすいですね。
サンプルアプリ
では、早速この概念を使ったサンプルアプリを作成して見ましょう。
今回はFlutterを使います。
つまり、フロントエンドにおいてこの概念を適用してみるということですね。
※サンプルはFlutterで、言語はDartですが、重要なのは概念です。他の言語を使う場合も応用可能です。また、Dartは難読な言語ではなく、JavaとJavaScriptを足して2で割ったような言語になっていますので、Clean Architectureを学ぶレベルの方は読めるかと思います。
アプリの概要
今回はRANDOM USER GENERATORのAPIを呼び出し、適当なユーザのリストを表示するアプリを開発してみます。
こんなイメージです。

- 「更新」ボタンをタップすると、5名分のユーザデータを表示する。
また、今回はUIの状態管理にFlutterのblocパターンを使っています。(ここでは全く重要ではありません。)
なお、コードはGitHubに公開しています。
設計
さて、早速Clean Architectureの概念を使って設計していきます。
今回は以下のように、data、domain、presentationの3つのコンポーネントに分割。
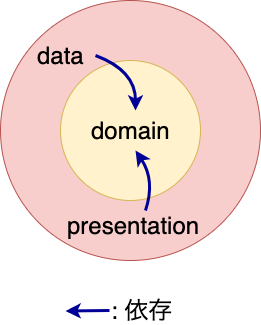
なお、ディレクトリ構造も掲載しておきます。
.
├── core
│ ├── ※省略
├── data
│ ├── datasources
│ │ └── random_user_generator_api.dart
│ ├── models
│ │ └── user_model.dart
│ └── repositories
│ └── user_repository_impl.dart
├── domain
│ ├── entities
│ │ └── user.dart
│ ├── repositories
│ │ └── user_repository.dart
│ └── usecases
│ └── fetch_users_usecase.dart
├── main.dart
└── presentation
├── bloc
│ ├── users_cubit.dart
│ └── users_state.dart
├── users_page.dart
└── widgets
├── user_list.dart
├── user_list_empty.dart
├── user_list_error.dart
├── user_list_item.dart
└── user_list_loading.dart
さて、ではそれぞれについて見ていきましょう。
各コンポーネントの内容
presentation
こちらはUIに関する処理を担います。
このディレクトリには以下の要素があります。
users_page.dart: 画面(ページ)を表示するためのコード。Flutterに依存。widgets: 画面に出すUIパーツ(FlutterなのでWidgetという)。bloc: UIの状態。Blocパターンの処理。UIとdomainを結びつける。
FlutterやBlocパターンの詳細は気にせずでOK。ここではUIに関するコードが書かれているということです。
ソースコードを少しだけ抜粋して見ていましょう。まぁ、Flutterではこんな感じでUIを書きます、という理解でOKです。
以下はusers_page.dartの一部です。
このように、UIを表示しています。
// 省略 @override Widget build(BuildContext context) { return Scaffold( appBar: AppBar( title: Text('Users'), ), floatingActionButton: BlocBuilder<UsersCubit, UsersState>( builder: (context, state) => FloatingActionButton( onPressed: () => { if (!(state is UsersLoading)) {context.read<UsersCubit>().fetchUsers(usersCount)} }, child: (state is UsersLoading) ? Icon(Icons.remove) : Icon(Icons.refresh), ), ), body: BlocListener<UsersCubit, UsersState>( listener: (context, state) { if (state is UsersError) { Scaffold.of(context) .showSnackBar(SnackBar(content: Text(state.message))); } }, child: BlocBuilder<UsersCubit, UsersState>( builder: (context, state) { if (state is UsersInit) { return UserListEmpty(); } else if (state is UsersError) { return UserListError(state.message); } else if (state is UsersAvailable) { return UserList(state.users); } return UserListLoading(); }, ), ), ); }
そして、このコンポーネントでは、bloc部分でdomainのusecaseを使います。
class UsersCubit extends Cubit<UsersState> { final FetchUsersUsecase _usecase; UsersCubit(this._usecase) : super(UsersInit()); void fetchUsers(int count) async { emit(UsersLoading()); final eitherUsers = await _usecase(FetchUsersUsecaseParams(count)); eitherUsers.fold((failure) { emit(UsersError(failure.message)); }, (users) { emit(UsersAvailable(users)); }); } }
コンストラクタ経由でusecaseのインスタンスを注入出来るようにしていますね。
domain
こちらはこのアプリ特有のビジネスロジックを実装します。
domainは別名、problem spaceともいいますので、こちらの方がイメージはしやすいかもしれません。
このディレクトリには以下の要素があります。
entities: コンポーネント間でデータをやりとりするためのプロトコル的なデータの定義repositories: 外部データをアクセスするためのインタフェースusecase: このアプリの機能を表現します
まずは、具体的な entitiesを見てみましょう。
こちらはuser.dartです。
class User { String name; String email; String thumbnailUrl; User({this.name, this.email, this.thumbnailUrl}); }
非常にシンプルですね。domainはpresentationやdataに依存されてますが、このUserは各コンポーネントとやりとりする際に利用されます。
次はrepositoriesを見てみましょう。
こちらはuser_repository.dartですが、単なるインタフェースとなっています。
abstract class UserRepository { Future<Either<Failure, List<User>>> getUserList(int count); }
なぜこのようなインタフェースを用意しているのか、といえば、domainはdataを呼び出す必要があるからです。
以下の図を見てください。
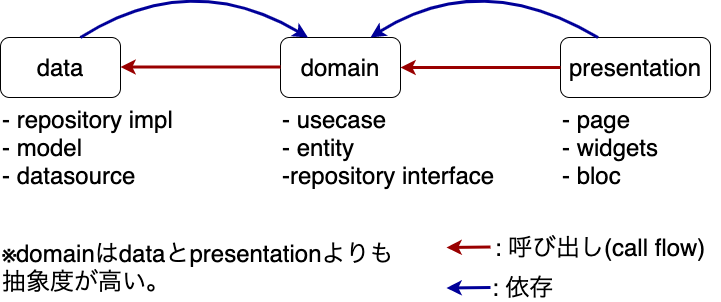
dataとdomainの呼び出しの順序(赤い矢印)に注目してください。
今回はAPI経由でデータを取得する必要があるため、domain(ビジネスロジック)側でdataを呼び出す必要があります。
しかし、依存性のルールを思い出してください。
domainは円の内側にあり、dataよりも抽象度が高いコンポーネントです。
そのコンポーネントが、より円の外側にある抽象度の低いコンポーネントを直接呼び出すことは依存性のルールに反します。
そこで、domainでは「APIからデータを取得する」という具体的な処理は記載せず、インタフェースを定義するにとどめているというわけです。
domain内で、その中にあるインタフェースに依存することで依存性のルールを守ります。
このようなテクニックは依存性逆転の原則(Dependency Inversion Principle)と呼ばれています。
ちょっとusecaseの1つであるfetch_users_usecase.dartを見てみましょう。
class FetchUsersUsecase extends Usecase<FetchUsersUsecaseParams, List<User>> { final UserRepository repository; FetchUsersUsecase(this.repository); @override Future<Either<Failure, List<User>>> call(FetchUsersUsecaseParams params) { return repository.getUserList(params.count); } } // 省略
コンストラクタでUserRepositoryを注入できるようにしていますね。
つまり、実行時にはこのインタフェースを実装したインスタンスが利用できるということです。
data
最後はdataです。
こちらは実際のデータソース(今回はAPI)からデータを取得し、domain側で利用できるように変換する処理が入っています。
models: APIで定義されているデータ構造datasources: APIにアクセスし生のデータを取得repositories: domainのrepositoryインタフェースの実装
まずは、modelsから見ていきましょう。
こちらはデータソースの概念を取り込んだデータ構造です。
例を見ましょう。こちらはuser_model.dartです。
class UserModel extends User { UserModel({String name, String email, String thumbnailUrl}) : super(name: name, email: email, thumbnailUrl: thumbnailUrl); factory UserModel.fromJson(Map<String, dynamic> json) { return UserModel( name: [json['name']['first'], json['name']['last']].join(' '), email: json['email'], thumbnailUrl: json['picture']['thumbnail'], ); } static List<UserModel> userListFromJson(Map<String, dynamic> json) { return json['results'].fold(List<UserModel>(), (prev, userJson) { prev.add(UserModel.fromJson(userJson)); return prev; }); } }
extends Userとなっていますが、これはdomainで定義してたUserというEntityです。
これを継承することで、このクラスのインスタンスをUserとしても使えるようにしています。
しかし、modelはentityと違い、このクラスのインスタンスは「APIから取得したJSONから作られることを知って」います。
それでは、次はrepositoriesの中にある、user_repository_impl.dartを見てみましょう。
class UserRepositoryImpl extends UserRepository { final RandomUserGeneratorApi api; UserRepositoryImpl(this.api); @override Future<Either<Failure, List<User>>> getUserList(int count) async { try { final userList = await api.fetchRandomUsers(count); return Right(userList); } on ServerException { return Left(ServerFailure()); } } }
extends UserRepositoryとあるように、domain内のUserRepositoryを継承しています。
このクラスのインスタンスをusercaseに注入することになります。
Dependency Injection
最後にDI(Dependency Injection)も見てみましょう。
今回、様々なクラスを作成しましたが、コンストラクタで依存しているインスタンスを注入してやる必要があります。
どこでDIするかは利用するフレームワークによっても変わってくると思いますが、ここではFlutterのエントリポイント付近で行います。
void main() { runApp(MyApp()); } class MyApp extends StatelessWidget { final http.Client _client = http.Client(); @override Widget build(BuildContext context) { return MaterialApp( onGenerateRoute: (settings) { if (settings.name == '/') { return _usersRoute(); } throw Exception('There is no such page: ${settings.name}'); }, ); } MaterialPageRoute _usersRoute() { const USERS_COUNT = 5; final api = RandomUserGeneratorApi(_client); final repository = UserRepositoryImpl(api); final usecase = FetchUsersUsecase(repository); final cubit = UsersCubit(usecase); return UsersPage.route(cubit, USERS_COUNT); } }
_usersRoute()というメソッドがDIです。
各種必要なインスタンスの生成を行い、最終的にはFlutterで利用できるWidget(ページ)を返しています。
これが今回作成したサンプルアプリの概要です。
必要に応じてソースコードも参照してみてください。
スーパーエンジニアと話して分かったClean Architectureの本質
さて、ここまではClean Architectureとはどんなものか、それを使ったアプリはどんな設計なのかを書いてきました。
ここからは、では実際にClean Architectureはどんな風に使われているか、についてうかがったことを書いていきたいと思います。
まず、今回開発したアプリはスーパーエンジニアの方の話、説明用のリポジトリ(こちらはprivateなものなので共有できません。。。)をベースに作成したもの。
そこで聞いたのは、そのrepoはあくまで「Clean Architectureの基本」であり、「production」用ではないとうこと。
ご厚意により、実際にプロダクションのプロジェクトをいくつか見せていただきましたが、domainやusecaseなど、Clean Architectureでよく出てくる名詞が使われていませんでした。
つまり、一見すると、このソースコードがClean Architectureに従っているのかは分かりません。
しかしimport文を観察すると、確かに依存関係が整理されています。 そして各コンポーネントに適切なユニットテストが存在します。
つまり、Clean Architectureです。
これにはとても衝撃を受けることに。
というのも、自分はClean Architectureを使うということは、usecaseやrepositoryなどといった名詞を使って教科書のように組むのだ、と考えていたから。
しかし、Clean Architectureの本質はあくまで依存性のルールに従ってコンポーネントを分割すること。
つまり、どんなディレクトリ構造にするか、クラスを作るかはその本質ではないということです。
実際にお話を伺うと、プロダクション向けの設計をする場合は様々な制約があるとのこと。
- 利用しているフレームワークは?
- 使う言語は?
- 使う言語やフレームワークの習慣(スタイルガイド)は?
- 使える工数は?
- アプリの規模は?
- 開発チームの習慣は?
などなどを考慮し、最適な設計を実現するとのことです。
これを聞いたとき、トップにいるエンジニアは常に「エンジニアリング」をしていると痛感し、今後の自分の考えも改める必要があると思いました。
結局、ソフトウェア設計において「このようにしておけば正解」というものは存在しないということ。
どのように設計するのが一番良いかプロジェクトごとに考える必要があり、その点において上級のソフトウェアエンジニアの存在意義があると感じました。
まとめ
Clean Architectureの本質は依存性のルールに従って関心の分離を図ること。
そうすることによって、変更や追加が容易で、テストが書きやすい(不具合が見つけやすい)設計とする。
どのようなクラスやディレクトリを作るかは、毎回プロジェクトの制約を考慮する必要がある。